










AI音乐创作
MusicLM
谷歌平台的AI作曲工具,用文字生成音乐
标签: AI音乐创作 语言模型音乐 Google AI工具 文本到音乐生成 创作系统平台 MusicLM网站 musicLM下载 musicLM是什么意思 musicLM生成的音乐片段 musicLM是什么

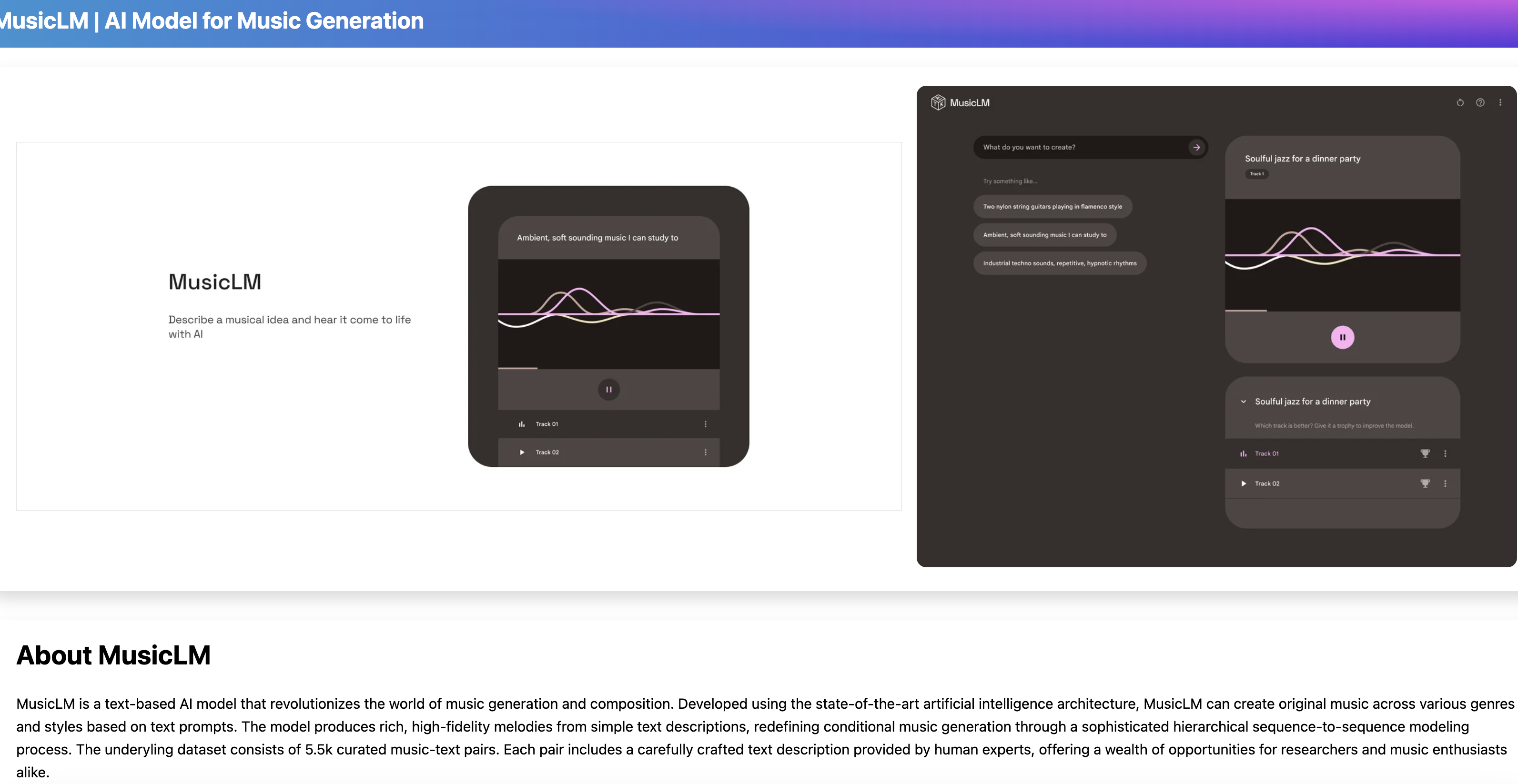
MusicLM,这是一个从文本描述中生成高保真音乐的模型,例如“由扭曲的吉他重复段支撑的平静的小提琴旋律”。MusicLM将条件音乐生成的过程转换为分层序列到序列的建模任务,它以24千赫的频率生成音乐,在几分钟内保持一致。我们的实验表明,MusicLM在音频质量和对文本描述的依从性方面都优于以前的系统。此外,我们还演示了MusicLM可以同时以文本和旋律为条件,因为它可以根据文本标题中描述的风格转换口哨和哼唱的旋律。为了支持未来的研究,我们公开发布了MusicCaps,这是一个由5.5k音乐文本对组成的数据集,由人类专家提供丰富的文本描述。
©️版权声明:本站所有资源均收集于网络,只做学习和交流使用,版权归原作者所有。若您需要使用非免费的软件或服务,请购买正版授权并合法使用。本站发布的内容若侵犯到您的权益,请联系站长删除,我们将及时处理。
类似网站







按住
Ctrl+D 或 ⌘+D
键,
把AI一八二收藏起来吧!
AI一八二收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具,推荐了AI学习开发的常用网站、框架和模型,帮助你加入人工智能浪潮,自动化高效完成任务! Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。

QQ扫码加群
 鄂公网安备42018502008087号
鄂公网安备42018502008087号